Support &
Documentation

Support &
Documentation
[Detailed description of scheduling | Calculating priority | Allocation policy on Kebnekaise ]
The batch system policy is fairly simple, and currently states that
If you submit a job that takes up more than your monthly allocation (remember running jobs take away from that), then your job will be pending with "Reason=AssociationResourceLimit" or "Reason=AssocMaxCpuMinutesPerJobLimit" until enough running jobs have finished. A job cannot start if it asks for more than your total monthly allocation.
You can see the current priority of your project (and that of others), by running the command sshare and look for the column marked 'Fairshare' - that shows your groups current priority.
The fairshare weight decays gradually over 50 days, meaning that jobs older than 50 days does not count towards priority.
Remember When and if a job starts depends on which resources it is requesting. If a job is asking for, say, 10 nodes and only 8 are currently available, the job will have to wait for resources to free up. Meanwhile, other jobs with lower requirements will be allowed to start as long as they do not affect the starttime of higher priority jobs.
The SLURM scheduler divides the job queue in two parts.
Basically what happens when a job is submitted is this.
When a job is submitted, the SLURM batch scheduler assigns it an initial priority. The priority value will increase while the job is waiting, until the job gets to the head of the queue. This happens as soon as the needed resources are available, provided no jobs with higher priority and matching available resources exists. When a job gets to the head of the queue, and the needed resources are available, the job will be started.
At HPC2N, SLURM assigns job priority based on the Multi-factor Job Priority scheduling. As it is currently set up, only one thing influence job priority:
Weights has been assigned to the above factors in such a way, that fair-share is the dominant factor.
The following formula is used to calculate a job's priority:
Job_priority = 1000000 * (fair-share_factor)
Priority is then calculated as a weighted sum of these.
The fair-share_factor is dependent on several things, mainly:
You can see the current value of your jobs fairshare factors with this command
sprio -l -u <username>
and your and your projects current fairshare value
sshare -l -u <username>
Note: that these values change over time, as you and your project members use resources, others submit jobs, and time passes.
Note: the job will NOT rise in priority just due to sitting in the queue for a long time. No priority is calculated merely due to age of the job.
For more information about how fair-share is calculated in SLURM, please see: http://slurm.schedmd.com/priority_multifactor.html
The allocation policy on Kebnekaise is somewhat complex, mainly due to the mixture of normal CPUs (of different kinds) and GPUs (of different kinds) on Kebnekaise. Thus, Kebnekaise's allocation policy may need a little extra explanation.
Thin (compute) nodes (Skylake)
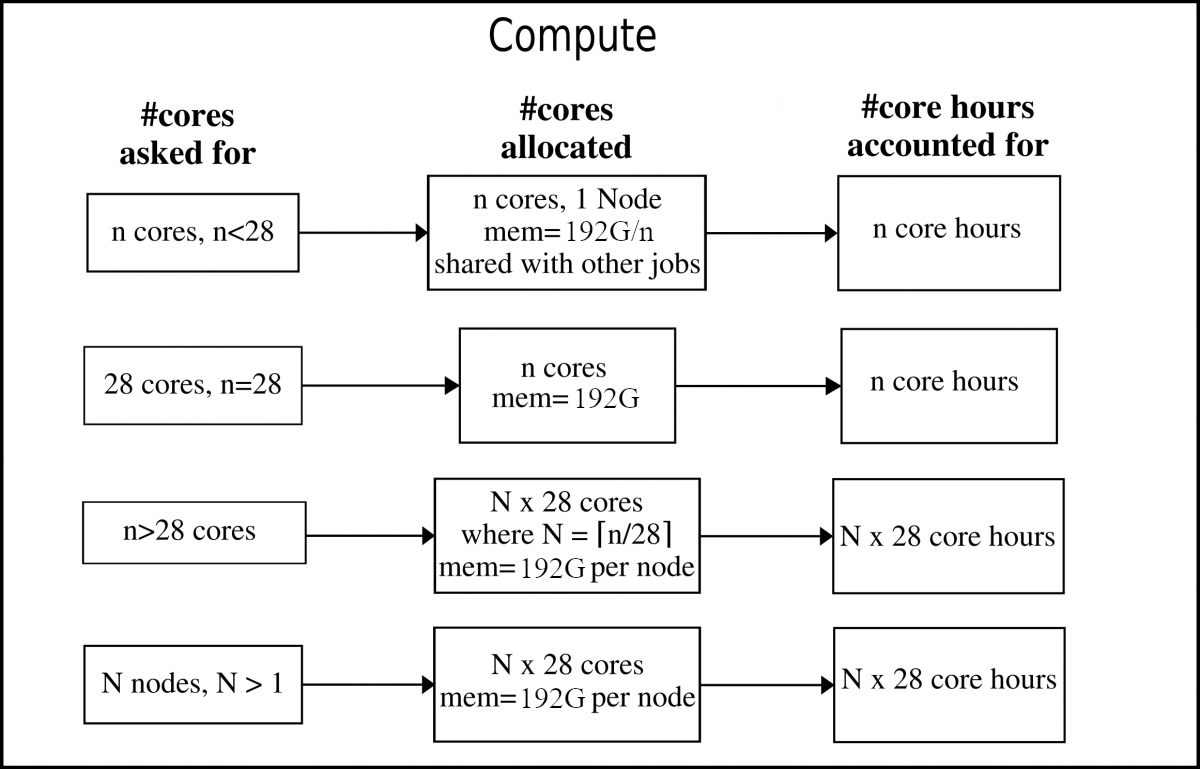 The compute nodes, or "thin" nodes, are the standard nodes with 192 GB memory (Skylake).
The compute nodes, or "thin" nodes, are the standard nodes with 192 GB memory (Skylake).
Note: As long as you ask for less than the number of cores than what there are in one node (28 cores), you will only be allocated for that exact number of cores. If you ask for more than 28 cores, you will be allocated whole nodes and accounted for that.
LargeMem nodes
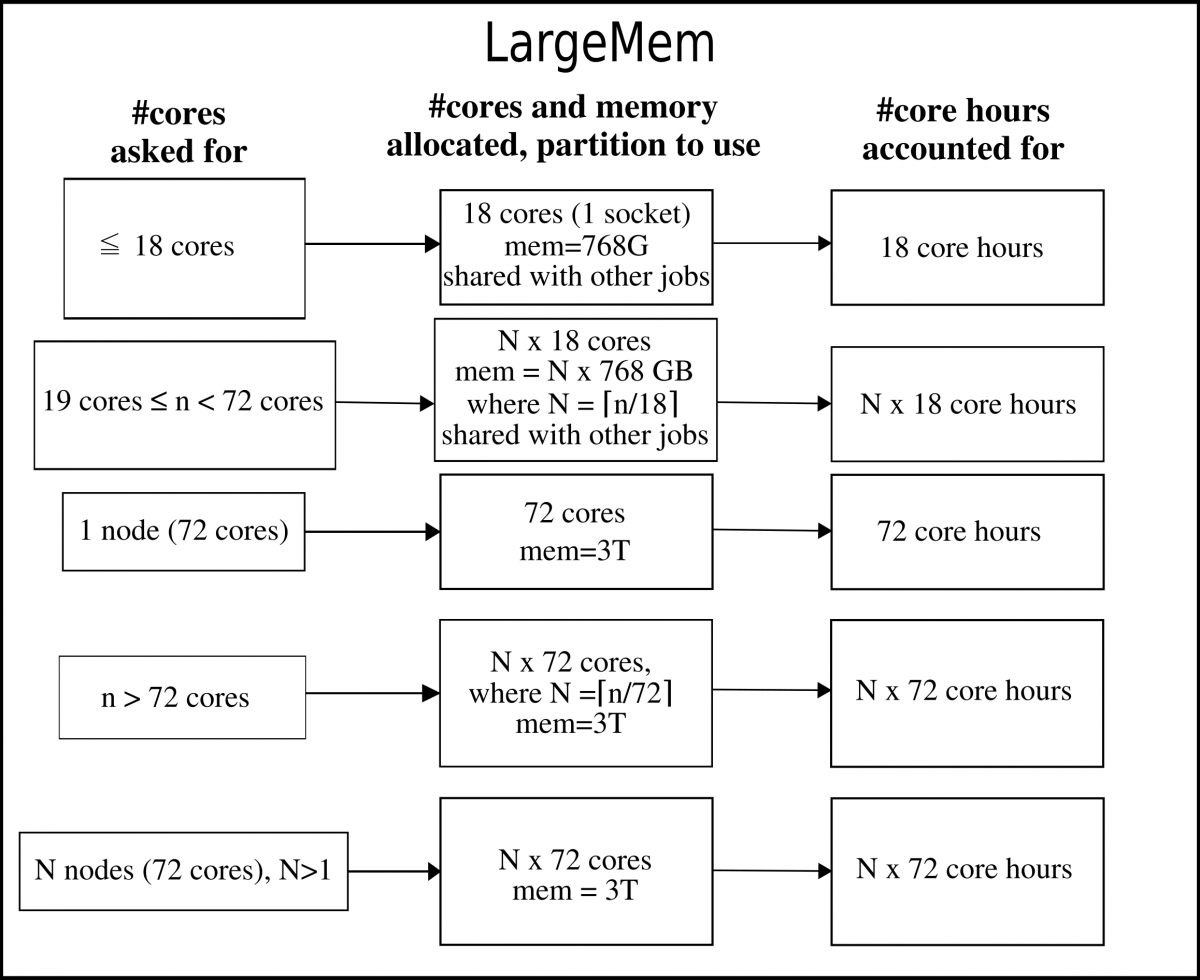 The largemem nodes have 3 TB memory per node.
The largemem nodes have 3 TB memory per node.
Note: these nodes are not generally available, and requires that your projects have an allocation of these.
The LargeMem nodes can be allocated per socket or per node.
GPU nodes
For core hour calculations, on a V100 GPU card each core hour on a full card allocates as 2 GPU-hours. The A100 GPU cards are allocated as 6 GPU-hours. Here follows some examples and a more detailed description for all types of GPU nodes.
NOTE: your project need to have time on the GPU nodes to use them, as they are considered a separate resource now. For the V100s and K80s you do not have to add a specific partition in the job script - you just use the SLURM command
#SBATCH --gres=gpu:<type-of-card>:x
where <type-of-card> is either v100 or a100 and x = 1, 2).
However, for A100s you also need to add a partition to the script, by using the SLURM command
#SBATCH -p amd_gpu
See more on the SLURM GPU Resources page.
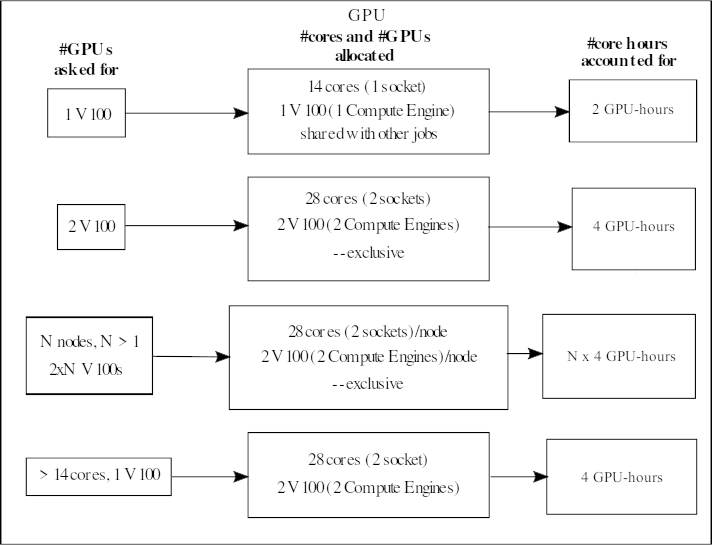 When asking for one V100 GPU accelerator card, it means you will get its 1 onboard compute engine (GV100 chip). The GPU nodes have 28 normal cores and 2 V100s (each with 1 compute engine). They are placed together as 14 cores + 1 V100 on a socket. If someone is using the GPU on a socket, then it is not possible for someone else to use the normal CPU cores of that socket at the same time.
When asking for one V100 GPU accelerator card, it means you will get its 1 onboard compute engine (GV100 chip). The GPU nodes have 28 normal cores and 2 V100s (each with 1 compute engine). They are placed together as 14 cores + 1 V100 on a socket. If someone is using the GPU on a socket, then it is not possible for someone else to use the normal CPU cores of that socket at the same time.
Your project will be accounted for 2 GPU-hours/hour if you ask for 1 V100.
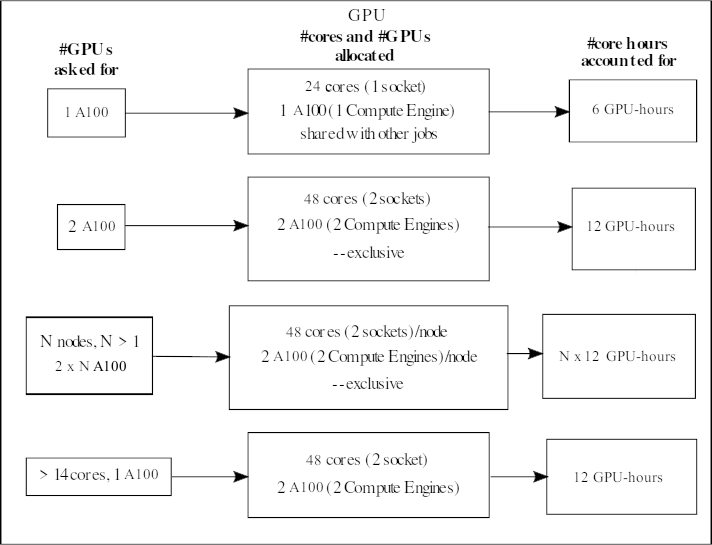 When asking for one A100 GPU accelerator card, it means you will get its 1 onboard compute engine. The AMD Zen3 A100 nodes have 48 normal cores and 2 A100s (each with 1 compute engine). They are placed together as 24 cores + 1 A100 on a socket. If someone is using the GPU on a socket, then it is not possible for someone else to use the normal CPU cores of that socket at the same time.
When asking for one A100 GPU accelerator card, it means you will get its 1 onboard compute engine. The AMD Zen3 A100 nodes have 48 normal cores and 2 A100s (each with 1 compute engine). They are placed together as 24 cores + 1 A100 on a socket. If someone is using the GPU on a socket, then it is not possible for someone else to use the normal CPU cores of that socket at the same time.
Your project will be accounted for 6 GPU-hours/hour if you ask for 1 A100.