Kebnekaise
![]()
![]()
Kebnekaise
Details:
[ Compute (Skylake-SP) nodes | Compute nodes (AMD Zen3) | Compute nodes (AMD Zen4) | Largemem nodes | GPU nodes (V100) ]
[ GPU nodes (A100) | GPU nodes (A40) | GPU nodes (MI100 AMD) | GPU nodes (A6000) | GPU nodes (L40s) | GPU nodes (H100) | GPU nodes (A40) ]
Kebnekaise is the current supercomputer at HPC2N. It is named after the massif of the same name, which has some of Sweden's highest mountain peaks (Sydtoppen and Nordtoppen). Just as the massif, the supercomputer Kebnekaise is a system with many faces.
Kebnekaise is being continuously updated with new hardware as old hardware is retired.
Kebnekaise timeline
Kebnekaise Celebration and HPC2N Open House was held 30 November 2017.
| Node Type | #nodes | CPU | Cores | Memory | Infiniband | Notes |
|---|---|---|---|---|---|---|
| Compute-skylake | 48 | Intel Xeon Gold 6132 | 2x14 | 192 GiB/node | EDR | |
| Compute-AMD Zen3 | 1 | AMD Zen3 (AMD EPYC 7763) | 2x64 | 1 TiB/node | EDR | |
| Compute-AMD Zen4 | 8 | AMD Zen4 (AMD EPYC 9754) | 2x128 | 768 GiB/node | HDR200 | These nodes run Ubuntu Jammy 22.04 LTS. |
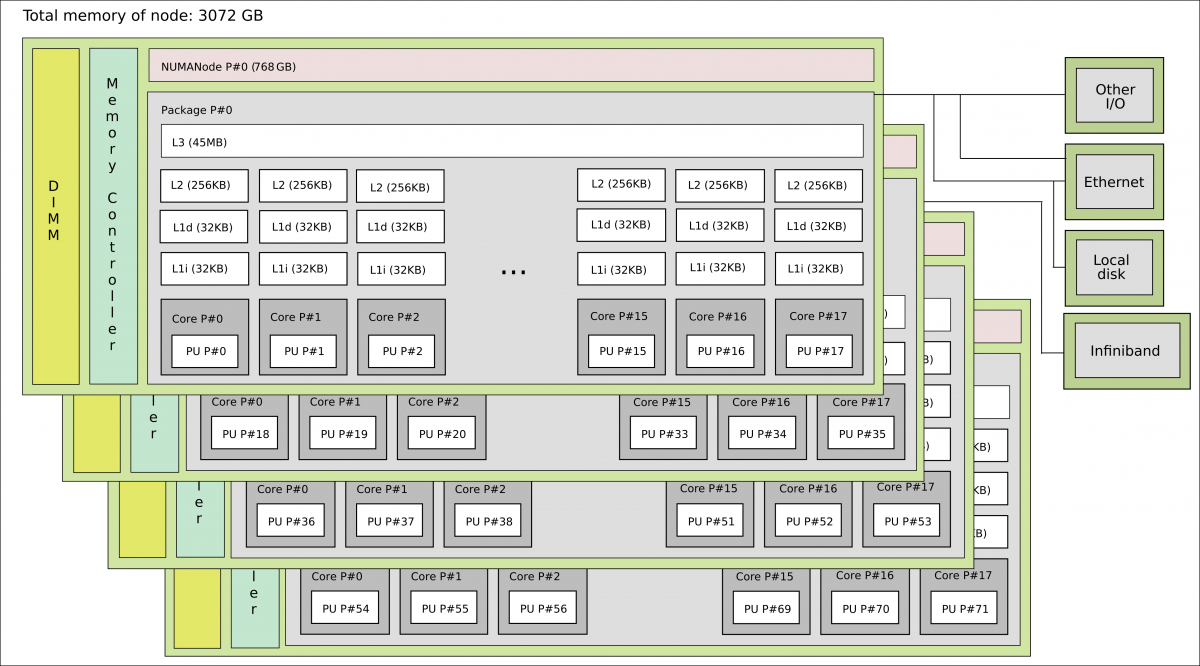
| Large Memory | 8 | Intel Xeon E7-8860v4 | 4x18 | 3072 GiB/node | EDR | Allocations for the Large Memory nodes are handled separately. |
| 2xV100 | 10 | Intel Xeon Gold 6132 2x NVidia V100 |
2x14 2x5120(CUDA) 2x640(Tensor) |
192 GiB/node | EDR | |
| 2xA100 | 2 | AMD Zen3 (AMD EPYC 7413) | 2x24 2x6912(CUDA) 2x432(Tensor) |
512 GiB/node | EDR | These nodes run Ubuntu Jammy 22.04 LTS. |
| 2xMI100 | 1 | AMD Zen3 (AMD EPYC 7413) | 512 GiB/node | HDR200 | These nodes run Ubuntu Jammy 22.04 LTS. | |
| 2xA6000 | 1 | AMD Zen4 (AMD EPYC 9254) | 384 GiB/node | HDR200 | These nodes run Ubuntu Jammy 22.04 LTS. | |
| 2xL40s | 10 | AMD Zen4 (AMD EPYC 9254) | 384 GiB/node | HDR200 | These nodes run Ubuntu Jammy 22.04 LTS. | |
| 4xH100 | 2 | AMD Zen4 (AMD EPYC 9454) | 768 GiB/node | HDR200 | These nodes run Ubuntu Jammy 22.04 LTS. | |
| 8xA40 | 1 | AMD Zen4 (AMD EPYC 9334) | 768 GiB/node | HDR200 | These nodes run Ubuntu Jammy 22.04 LTS. | |
| 6xL40s | 2 | AMD Zen4 (AMD EPYC 9334) | 768 GiB/node | HDR200 | These nodes run Ubuntu Jammy 22.04 LTS. |
There is local scratch space on each node, which is shared between the jobs currently running. Connected to Kebnekaise is also our parallel file system Ransarn (where your project storage is located), which provide quick access to files regardless of which node they run on. For more information about the different file systems that are available on our systems, read the Filesystems and Storage page.
All nodes are running Ubuntu Jammy (22.04 LTS). We use EasyBuild to build software and we also use a module system called Lmod. We are constantly improving the portfolio of installed software. The software page currently lists only a few of the installed software packages. Please log in to Kebnekaise (regular: kebnekaise.hpc2n.umu.se or ThinLinc: kebnekaise-tl.hpc2n.umu.se) for a list of all available software packages. Note that some packages may be different on the AMD nodes. Login to kebnekaise-amd.hpc2n.umu.se to check the software on those.
NOTE: There is a special login node for the A100 GPUs that is AMD Zen3 (AMD EPYC 7313) and with 1 A100 card: kebnekaise-amd (for ThinLinc: kebnekaise-amd-tl). It is also running Ubuntu Jammy 22.04 like the A100 nodes, and is recommended for when you are using the A100 GPUs, or any other node running Ubuntu Jammy, as it allows you to see which software is available on them.
Kebnekaise is using SLURM for job management and scheduling.
| Compute-skylake Nodes | 87 TFlops/s |
| Large Memory Nodes | 34 TFlops/s |
| 2xV100 Nodes | 75 TFlops/s |
Do note that running all 28 cores with lots of AVX (on the normal CPUs) will limit the clock to at absolute maximum 2.9 GHz per core, and probably no more than 2.5.
The AVX clock frequency != the rest of the CPUs clock frequency and has a lower starting point and lower max boost.
Architecture is Intel Xeon Gold 6132 (Skylake-SP).
Each core has:
The memory is shared in the whole node, but physically 96 GB is placed on each NUMA island. The memory controller on each NUMA node has 6 channels.
The Intel Xeon Gold 6132 has two AVX-512 FMA units per core.
Some more information can be found here and here.
| Intel Xeon Gold 6132 (Skylake-SP) | |
|---|---|
| Instruction set | SSE4.2, AVX, AVX2, AVX-512 |
| SP FLOPs/cycle | 64 (32 per AVX-512 FMA unit) |
| DP FLOPs/cycle | 32 (16 per AVX-512 FMA unit) |
| Base Frequency | 2.6 GHz |
| Turbo Mode Frequency (single core) | |
| Turbo Mode Frequency (all cores) | |
Thus it is possible to run 32 double precision or 64 single precision floating point operations per second per clock cycle within the 512-bit vectors, as well as eight 64-bit and sixteen 32-bit integers, with up to two 512-bit fused-multiply add (FMA) units.
Architecture is AMD Zen3 (AMD EPYC 7763 64-Core)
- The CPU-only node have 2 CPU sockets with 64 cores each and 1TB of memory (or 8020MB/core usable)
Architecture is AMD Zen4 (AMD EPYC 9754 128-Core)
- The CPU-only nodes have 2 CPU sockets with 128 cores each and 768 GB of memory (or 2516MB/core usable)
There are 18 cores on each of the 4 NUMA islands. The cores on each NUMA island share 768 GB memory, but have access to the full 3072 GB on the node. The memory controller on each NUMA island has 4 channels.
We have 10 nodes with NVidia V100 (Volta) GPUs. Each CPU core is identical to the cores in the Skylake compute nodes and in addition to that the nodes each have
One V100 GPU is located on each NUMA island.
- The GPU enabled nodes (AMD EPYC 7413 24-Core) have 2 CPU sockets with 24 cores each, i.e. 48 in total and 512GB memory (or 10600MB/core usable)
The information that were used in creating the images for the compute node and largemem node on this page are generated with the lstopo command.