Hardware
![]()
![]()
Hardware
Understanding of the underlying architecture in Abisko is essential in obtaining optimal performance for all but trivial use cases.
Abisko is comprised of 318 compute nodes, each with 4 sockets of AMD Opteron 6238 (also known as Interlagos, Bulldozer core). They are clocked at 2.6GHz nominally, with overclock/TurboMode of up to 3.2GHz depending on how many cores are idle.
The 308 thin nodes have 128GB of DDR3-1600 RAM, the remaining 10 fat nodes have 512GB of DDR3-1066 RAM.
The Abisko compute nodes are to be considered complex Non-Uniform Memory Access (NUMA) machines, where the layout of memory in relation to the computing cores used can make a huge difference in real-life performance. Even though they physically have 4 CPU sockets with 12 cores each, they are in fact architecturally 8 NUMA Nodes with 6 cores each. One confusing aspect to note is that one such NUMANode is simply called a node in AMD documentation, naturally this can be confused with a compute node (which we also tend to call just a node at times).
Resources within a NUMANode are tightly coupled with a high speed crossbar switch which means that access to resources within a NUMANode are fast. The figure below details a NUMANode in a thin compute node.

Within a NUMANode each Compute Unit consists of two cores that shares L2 cache and FPU. The L3 cache is shared between all Compute Units in the NUMANode.
These NUMANodes are connected to each other with HyperTransport 3.0 links. The bandwidth is limited to 12GB/s between the two NUMANodes in a socket and 6GB/s to other NUMANodes as shown in the following figure taken from the AMD documentation:
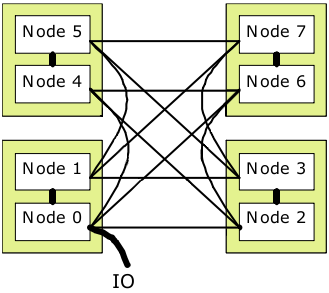
To optimize the performance of a compute job one has to take care to ensure that the memory used by a compute core is placed as optimal as possible in this rather complex memory hierarchy. The obvious recommendation is to use resources within a NUMANode if at all possible, as this will yield the optimum performance. Accessing resources within the same socket is also pretty efficient and only one full-width HyperTransport hop away. Moving beyond the socket you need to be aware of the limitations imposed by the half-width HyperTransport links and the link topology.
It is thus best to view an Abisko compute node as multiple 6-core islands with a really fast interconnect for communicating with the other 6-core islands within the same compute node.
http://support.amd.com/us/Processor_TechDocs/42301_15h_Mod_00h-0Fh_BKDG.pdf
http://www.siliconmechanics.com/files/BulldozerInterlagosInfo.pdf
http://www.olcf.ornl.gov/wp-content/uploads/2012/01/TitanWorkshop2012_Day1_AMD.pdf